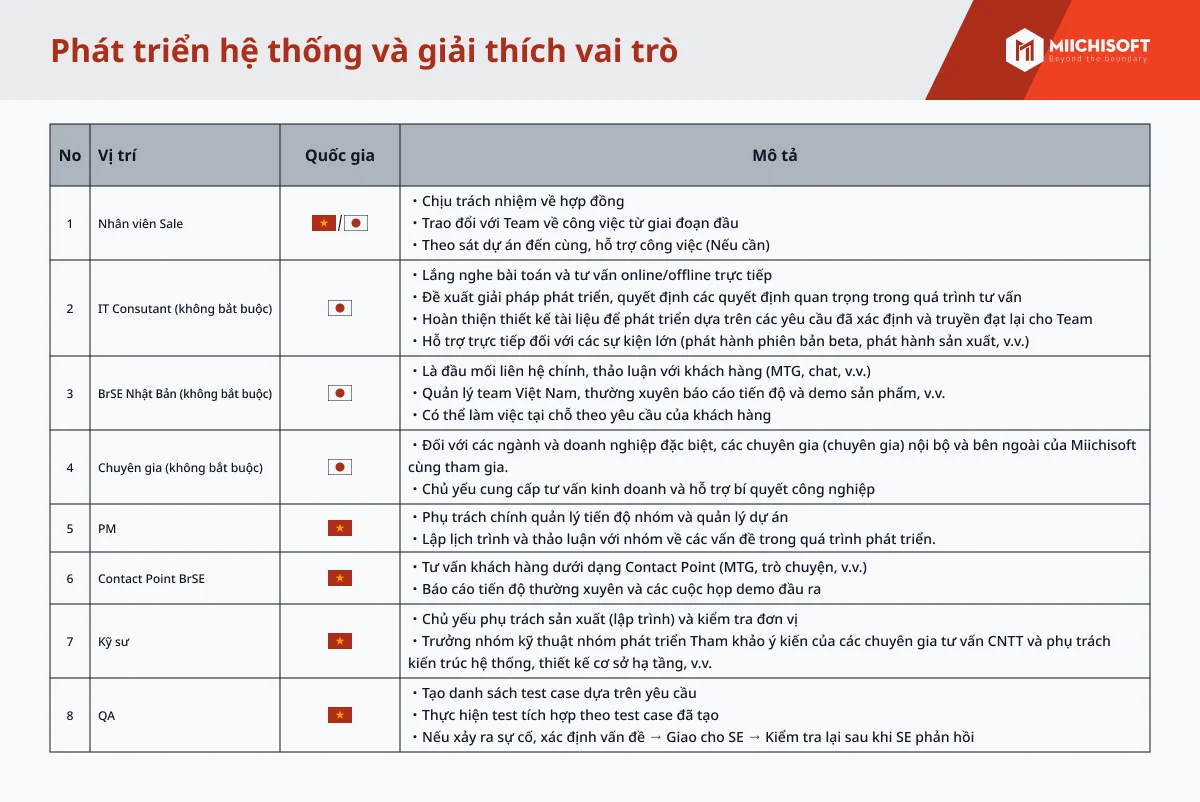
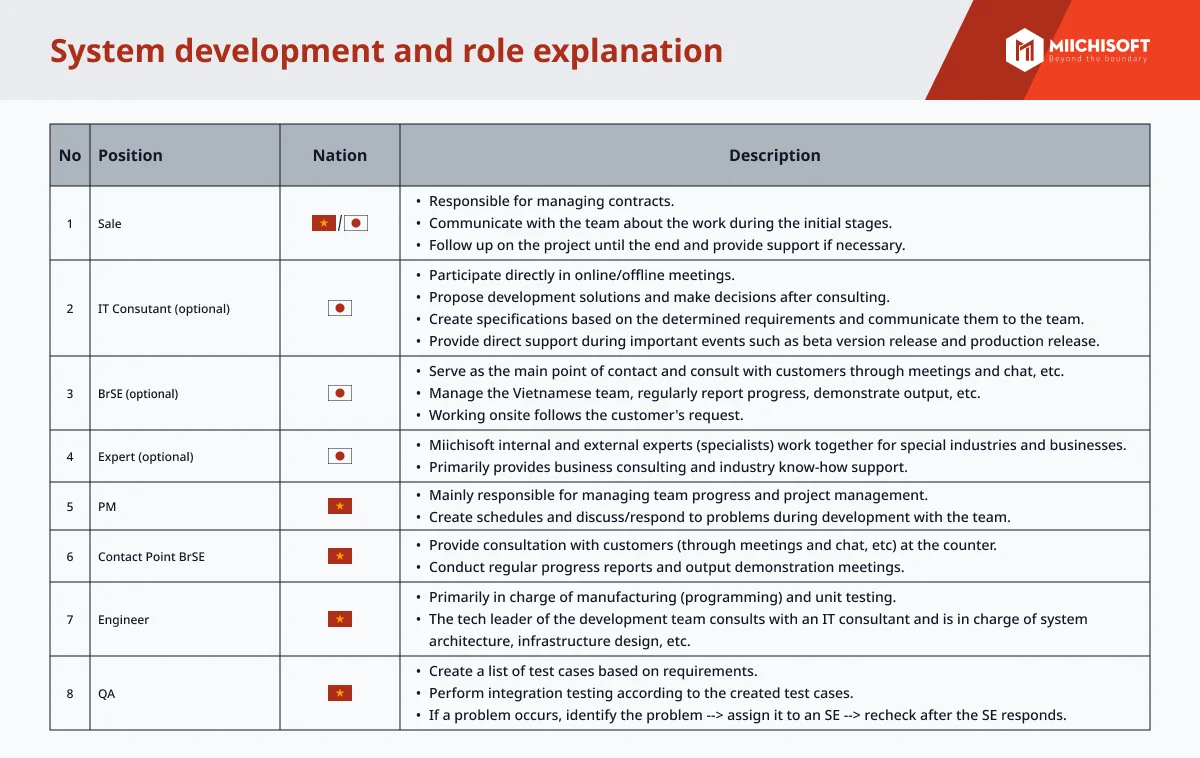
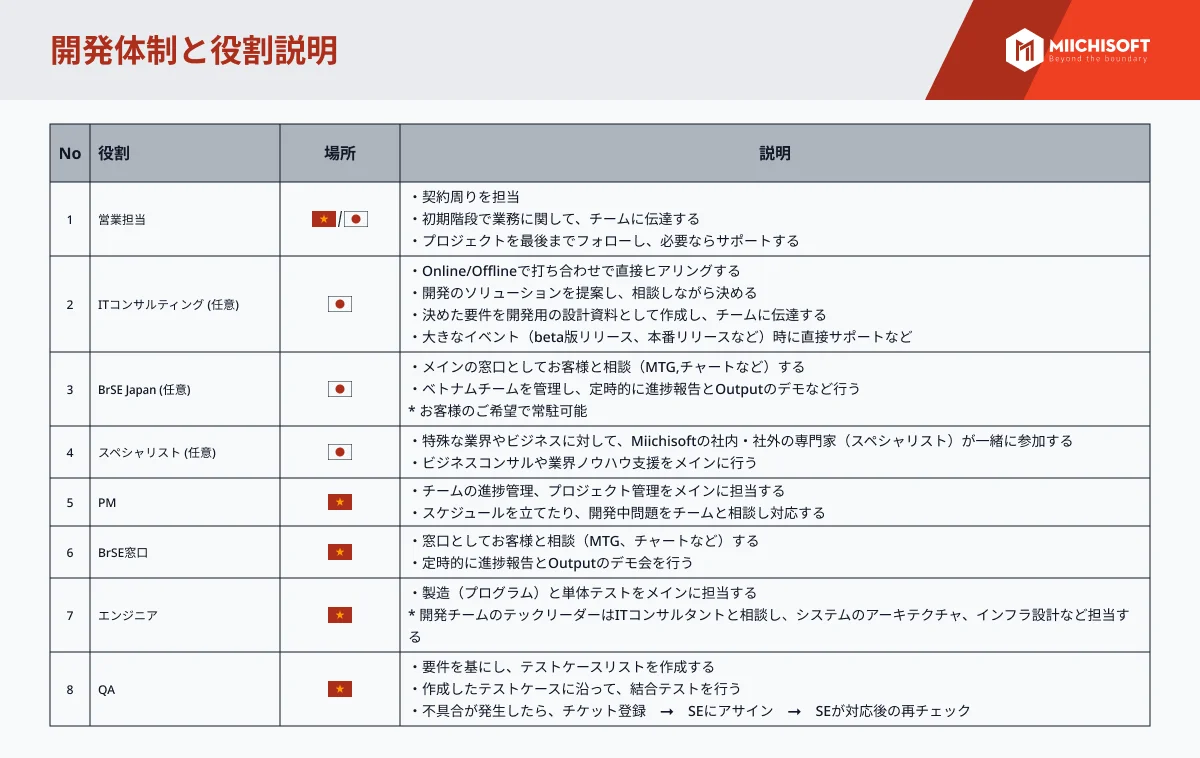
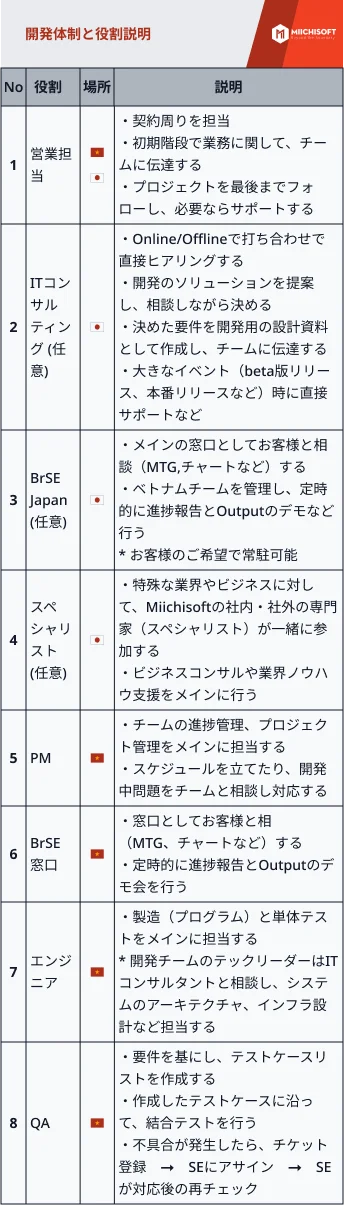
が生成AIの風景を再構築する方法-1-1.png)
近年、大規模な言語モデルの発展により、自然言語処理分野で顕著な進歩がなされ、生成AIの実用化が急速に進んでいます。しかしながら、これらの強力なモデルには克服すべき課題も存在します。その中で特に大きな問題の1つが、「幻覚」現象です。これは、大規模言語モデル(LLM)が正確でない情報、虚偽の情報、または裏付けのない情報を生成してしまうことを指します。この記事では、非常に有用で広く普及している検索拡張生成(Retrieval Augmented Generation)に焦点を当て、上記の問題に立ち向かうために使用されるテクニックについて学びます。お見逃しなく、最適なソリューションの探求にお役立てください。
通常の大規模言語モデル(LLMs)は、静的であるため、更新された情報や最新のデータを取り込むことができません。彼らのトレーニングデータはある特定の時点で「凍結」されており、その後の出来事や変更には対応できません。また、LLMsは一般的なタスク向けにトレーニングされており、特定のドメインの知識が不足しています。このため、企業独自のデータや要件に対応できません。
1. RAG(Retrieval Augmented Generation)とは
1.1. 検索拡張生成(RAG)とは
Meta AI(メタ、当時はFacebook)の研究者は、知識集約型のタスクに対処するために「検索拡張生成(RAG)」と呼ばれる手法を導入しました。RAG (Retrieval Augmented Generation)は、情報検索コンポーネントとテキストジェネレーターモデルを組み合わせたもので、微調整可能であり、内部知識をモデル全体を再トレーニングする必要なく、効率的な方法で変更できます。
RAGの手法の基本的なフローは、文章検索によって関連する文章を抽出し、それを大規模言語モデル(LLM)にプロンプトとして渡すことです。今回のケースでは、RAGの手法の中でも一般的な文章をベクトルに変換し、これらのベクトルデータをベクトルデータベース(Vector DB)に保存し、その後、類似度検索(Similarity Search)を行いました。
1.2. Generative AIアプリケーションの精度とパフォーマンスの向上させる 4つのヒント
OpenAIのChatGPTやAnthropicのClaudeなど、大規模言語モデル(LLM)をベースに構築された製品は非常に優れていますが、同時にいくつかの欠陥も抱えています。現行のLLMは強力である一方で、以下に示すようないくつかの欠点が存在します。
- LLMは静的です。つまり、「時間が固定」されており、最新の情報にアクセスできません。巨大なトレーニングデータセットを更新することは現実的ではありません。
- LLMはドメイン固有の知識が不足しています。一般的なタスク向けに訓練されており、企業のプライベートデータに通じていません。
- これらのモデルは「ブラックボックス」として機能します。LLMが結論に至るまでにどの情報源を検討したかを理解するのは容易ではありません。
- また、これらのモデルは非効率的で、作成には膨大な費用がかかります。基盤モデルを構築し、展開するためには財政的および人的なリソースが必要であり、多くの組織がこれに対応できるわけではありません。
残念ながら、これらの問題は生成AIアプリケーションの精度に悪影響を与えます。通常のチャットボットデモよりも厳格な要件を持つビジネスアプリケーションでは、「そのまま使用」するだけのLLMをプロンプト以外で変更せずに利用すると、特にコンテキストに依存するタスクにおいてパフォーマンスが低下します。
この投稿では、これらの欠点に対処するために取得拡張生成(RAG)が推奨される理由を検討し、RAGのメカニズムについて詳しく説明し、多くの企業が生成AIアプリケーションのパフォーマンス向上のためにRAGを選択する理由を解説します。
2. 現在の大規模言語モデル (LLM) の3つの課題
ChatGPTのトレーニング データの「カットオフ ポイント」は 2021 年 9 月でした。先月に起こったことについて ChatGPT に質問すると、質問に事実に基づいて答えられないだけではありません。 おそらく、非常に説得力のある真っ赤な嘘を思いつくでしょう。 私たちは通常、この行動を「幻覚」と呼んでいます。
ChatGPTのような LLM が非常に明るいと感じる理由は、企業全体に相当するオープン ソース コード、ライブラリに相当する書籍、生涯にわたる会話、科学データセットなど、膨大な量の人間の創造的な成果を彼らが見てきたからです。しかし、重要なことに、 このコアトレーニングデータは静的です。
OpenAI は 2021 年に ChatGPT の背後にある基盤モデル (FM) のトレーニングを終了した後、世界に関する追加の更新情報を受け取りませんでした。 重要な世界的出来事、気象システム、新しい法律、スポーツ イベントの結果、そして上の画像に示されているように、最新の自動車の操作手順には依然として無関心です。
2.1. 大規模言語モデル(LLM)の静的な特性
検索拡張生成(RAG)は、外部データベースから最新およびコンテキスト固有の情報を取得し、LLMが生成タスクを実行する際に利用可能にするアーキテクチャです。独自のビジネスデータや世界情報を保存し、LLMが生成時にこれを利用できるようにすることで、幻覚の可能性を軽減し、生成AIアプリケーションのパフォーマンスと精度を向上させます。
2.2. 特定のドメインにおける知識の不足
現行のLLMの2番目の主な欠点は、優れた知識コーパスにもかかわらず、ビジネスの詳細、要件、顧客ベース、およびアプリケーションが実行されているコンテキスト(電子メールなど)を把握していない点です。RAGは、生成時に生成AIアプリケーションのLLMに追加のコンテキストと事実情報を提供することで、この2つ目の問題に対処します。これには、顧客記録から劇中のセリフの段落、製品仕様、現在の在庫、音声、歌などのオーディオなど、あらゆる情報が含まれます。LLMは、提供されたコンテンツを使用して、情報に基づいた回答を生成します。
2.3. 検索拡張生成により透明性向上
RAG(Retrieval Augmented Generation)は、最新の情報や特定の領域に関連するデータの課題に対処するために開発されました。この手法は、研究論文で使用された重要なデータの出典を引用することと同様に、生成AIアプリケーションが情報源を提供できるようにもします。
RAGを活用することで、生成AIアプリケーションの内部動作を監査し理解することが容易になります。これにより、エンドユーザーは、生成AIアプリケーションが回答を生成する際に使用したソースドキュメントに直接アクセスし、信頼性を確認することができます。最終的に、この統合アプローチにより、法律業界や他の領域において、信頼性の高い情報と効果的な意思決定が可能となります。
3. RAGの主要な導入理由3つ
生成AIアプリケーションのパフォーマンス向上を図るには、RAG以外にも主要な3つのオプションが考えられます。なお、RAGが今日でも多くの企業によって主要な手段として採用され続けている理由を理解するために、これらの選択肢について調査を行ってみましょう。
3.1. 独自の基礎モデルの構築に取り組む
OpenAI の Sam Altman 氏は、ChatGPT の背後にある基盤モデルをトレーニングするのに約 1 億ドルかかると見積もっています。
すべての企業やモデルがこれほど多額の投資を必要とするわけではありませんが、ChatGPT の価格は、今日の技術で洗練されたモデルを作成するにはコストが大きな課題であることを浮き彫りにしています。
生のコンピューティングコストに加えて、人材不足の問題にも直面することになります。このようなモデルやあらゆるものを作成するための多くの技術的課題に取り組むには、機械学習の博士号取得者、一流のシステム エンジニア、高度なスキルを持つ運用担当者からなる専門チームが必要です。 世界の他の AI 企業も、同じ稀有な人材を狙っています。
もう 1 つの課題は、有能な基礎モデルを作成するために必要なデータセットを取得、サニタイズ、ラベル付けすることです。 たとえば、あなたが法的証拠開示会社で、法的文書に関する質問に答えるためにモデルをトレーニングすることを検討しているとします。 その場合、法律の専門家に何時間もかけてトレーニング データのラベル付けをしてもらうことも必要になります。
十分な資本にアクセスでき、適切なチームを編成し、適切なデータセットを取得してラベルを付け、実稼働環境でモデルをホストするための多くの技術的ハードルを克服できたとしても、成功の保証はありません。 業界では、いくつかの野心的な AI スタートアップ企業が誕生しては消えていくのを見てきましたが、今後さらに多くの失敗が見られると予想されます。
3.2. ドメインデータに基づくモデル微調整
微調整は、新しいデータに基づいて基礎モデルを再トレーニングするプロセスです。 確かに、基礎モデルを最初から構築するよりも安くなる可能性があります。 それでも、このアプローチには、基礎モデルの作成と同じ多くの欠点があります。つまり、希少で深い専門知識と十分なデータが必要であり、実稼働環境でモデルをホストするコストと技術的な複雑さは解消されません。
現在、LLM(Language Model)がコンテキスト検索用のベクトル データベースと組み合わせられるようになったことから、微調整は実現可能なアプローチではありません。 OpenAI などの一部のLLM プロバイダーは、最新世代モデルの微調整をサポートしなくなりました。
微調整は、LLM 出力を改善するための時代遅れの方法です。 対象分野の専門家による、コストと時間のかかる繰り返しのラベル付け作業と、品質のドリフト、定期的な更新の欠如によるモデルの精度の望ましくない逸脱、またはデータ分布の変化を継続的に監視する必要がありました。
データが時間の経過とともに変化すると、微調整されたモデルの精度も低下する可能性があり、よりコストと時間がかかるデータのラベル付け、継続的な品質の監視、および繰り返しの微調整が必要になります。
車を販売するたびにモデルを更新して、生成AIアプリケーションに最新の在庫データが含まれるようにすることを想像してください。
3.3. 幻覚の軽減には、プロンプトエンジニアリングだけでは十分ではありません。
プロンプトエンジニアリングとは、モデルに提供した指示をテストして微調整し、モデルを意図したとおりに実行できるようにすることを意味します。
また、コードをいくつか変更するだけで生成AIアプリケーションのLLMに提供される命令をすぐに更新できるため、生成AIアプリケーションの精度を向上させるための最も安価なオプションでもあります。
LLMが返す応答を改良しますが、新しいコンテキストや動的なコンテキストをLLMに提供することはできないため、生成AIアプリケーションは依然として最新のコンテキストを欠き、幻覚の影響を受けやすくなります。
4. 検索拡張生成(RAG)はどのように仕組むか?
4.1. 検索拡張生成の仕組み
RAGが生成時に、元のプロンプトや質問とともに、「コンテキスト ウィンドウ」を通じて追加の関連コンテンツをドメイン固有のデータベースからLLMに渡す方法について説明しました。
LLMのコンテキスト ウィンドウは、特定の瞬間におけるLLMの視野です。RAGは、LLMが確認する重要なポイントを含むキューカードをかざすようなもので、重要なデータを組み込んだより正確な応答を生成するのに役立ちます。
RAGを理解するには、まずセマンティック検索を理解する必要があります。セマンティック検索は、ユーザーのクエリ内のキーワードを単に一致させるのではなく、ユーザーのクエリの本当の意味を見つけて関連情報を取得しようとします。セマンティック検索は、ユーザーの正確な単語だけでなく、ユーザーの意図により適合する結果を提供することを目的としています。
が2024年の生成AIの風景を再構築する方法 1")
この図は、ドメイン固有の独自データからベクトルデータベースを作成する方法を示しています。ベクトルデータベースを作成するには、埋め込みモデルを介してデータを実行してデータをベクトルに変換します。
埋め込みモデルは、データをベクトル、つまり数値の配列またはグループに変換するLLMの一種です。上の例では、最新のボルボ車を操作するための真実を含むユーザーマニュアルを変換していますが、データはテキスト、画像、ビデオ、またはオーディオである可能性があります。
理解しておくべき最も重要なことは、ベクトルは入力テキストの意味を表すということです。これは、テキストを声に出して話した場合に他の人間が本質を理解するのと同じ方法です。コンピュータが保存されたデータの数値表現に基づいて意味的に類似した項目を検索できるように、データをベクトルに変換します。
次に、ベクトルをベクトルデータベースに格納します。ベクターを作成し、そのベクターをデータベースに取り込み、リアルタイムでインデックスを更新することで、GenAIアプリケーションのLLMの最新性の問題を解決できることを思い出してください。
たとえば、最新の製品のベクターを自動的に作成し、新製品を発売するたびにインデックスに更新/挿入するコードを作成できます。会社のサポートチャットボットアプリケーションは、RAGを使用して、製品の入手可能性に関する最新情報と、チャットしている現在の顧客に関するデータを取得できます。
4.2. 自然言語でデータをクエリできるベクトルデータベースの利用
ベクトルデータベースには、ターゲットデータの数値表現が組み込まれ、これによりセマンティック検索が可能になりました。エンドユーザーがあいまいな自然言語でクエリを作成するケースにおいて、ベクトルデータベースはセマンティック検索のユースケースで力を発揮します。
4.3. セマンティック検索: クエリを埋め込みに変換し、ベクトルデータベースで類似エントリを検索する仕組み
最初に、独自のデータを埋め込みに変換します。ユーザーがクエリまたは質問を行うと、その自然言語検索用語を埋め込みに翻訳します。
次に、これらの埋め込みをベクターデータベースに送信します。データベースは「最近傍」検索を実行し、ユーザーの意図に最もよく似たベクトルを見つけます。ベクトルデータベースが関連する結果を返すと、アプリケーションはその結果をコンテキストウィンドウ経由で言語モデルに提供し、生成タスクの実行を促します。
が2024年の生成AIの風景を再構築する方法 2")
言語モデルはベクターデータベースから最も適切で根拠のある事実にアクセスできるようになりました。これにより、アプリケーションはユーザーに対して正確な答えを提供できます。RAGは幻覚の可能性を軽減します。
5.よくある質問(FAQ)
質問1: 検索拡張生成(RAG)とは何ですか?
回答: RAGは、ユーザーのクエリに応答するために外部から取得した情報を使い、その情報をベースに大規模な言語モデル(LLM)が応答を生成するプロセスです。これにより、AIが発する幻覚を減らし、より事実ベースの回答を提供することができるようになります。
質問2: 「幻覚」現象とは何ですか?
回答: 幻覚現象とは、大規模言語モデル(LLM)が不正確な情報や虚偽の情報、裏付けのない情報を生成することを指します。これにより、モデルの出力が信頼できなくなる可能性があります。
質問3: RAG(検索拡張生成)の基本的な仕組みは何ですか?
回答: RAGは、元のプロンプトや質問に関連する情報をドメイン固有のデータベースから検索し、その情報を含んだコンテキストウィンドウとともに大規模言語モデル(LLM)へ提供することで、より精度の高い応答を生成します。
質問4: ベクトルデータベースの作成はどのように行われますか?
回答: ベクトルデータベースは、埋め込みモデルを使用してデータをベクトル(数値の配列)に変換し、これらのベクトルをデータベースに格納することで作成されます。
6. 結論
セマンティック検索と検索拡張生成は、生成AI 応答の関連性向上を通じて、エンドユーザーに卓越したエクスペリエンスをもたらします。基礎モデルの構築、既存モデルの微調整、またはプロンプトエンジニアリングのみの実行とは異なり、RAGは最新性とコンテキスト固有の問題に効率的かつ低リスクで同時に対処します。その主要な目的は、個人データへのアクセスが必要な質問に対して、状況に応じた詳細な回答を提供することです。
Miichisoftは、ベトナムのテクノロジー企業として、クロスプラットフォーム開発で数々の成功事例を積み重ねています。Miichisoftは、RAGテクノロジーを活用したソリューションの開発に豊富な経験を有しています。詳細については、当社のウェブサイトをご覧ください。