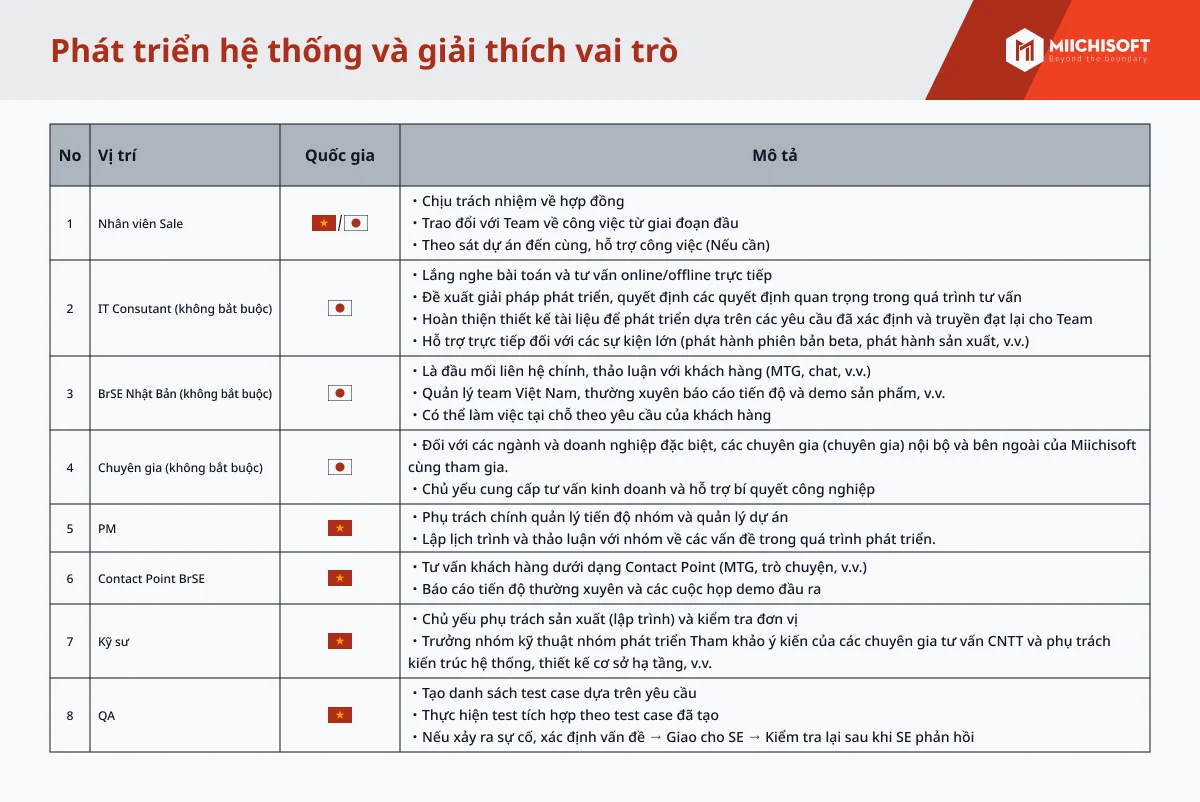
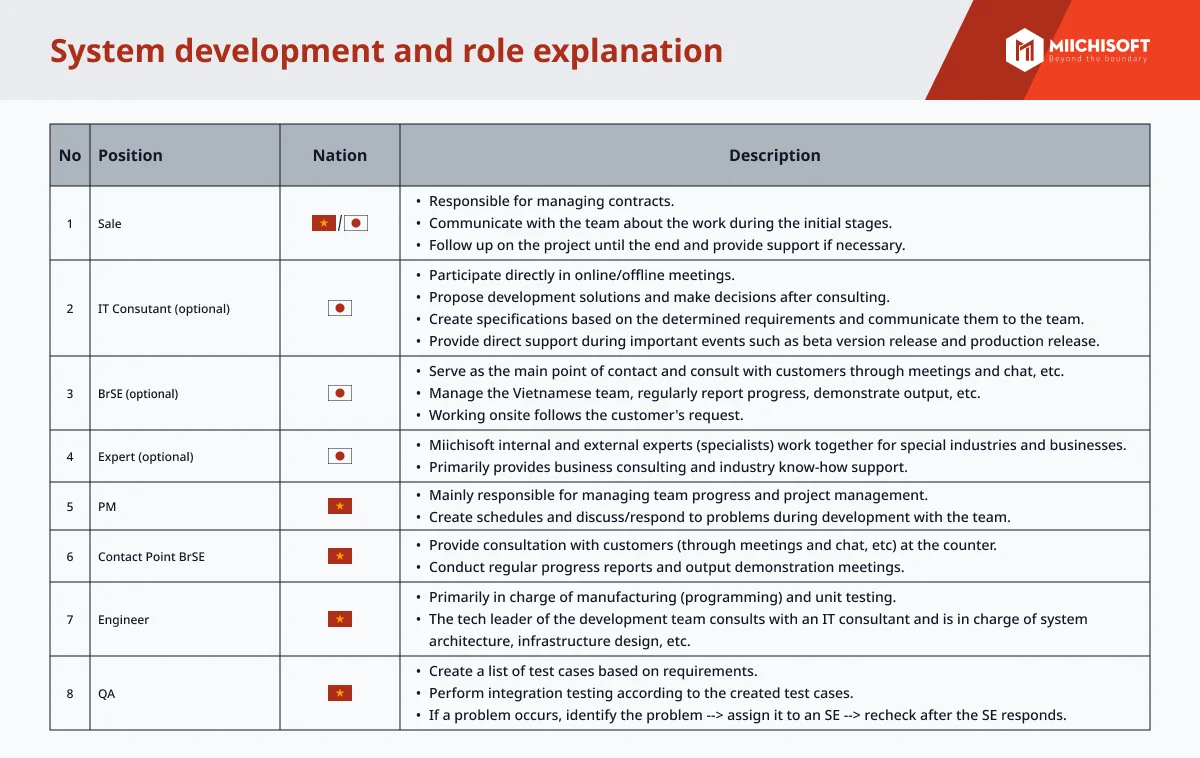
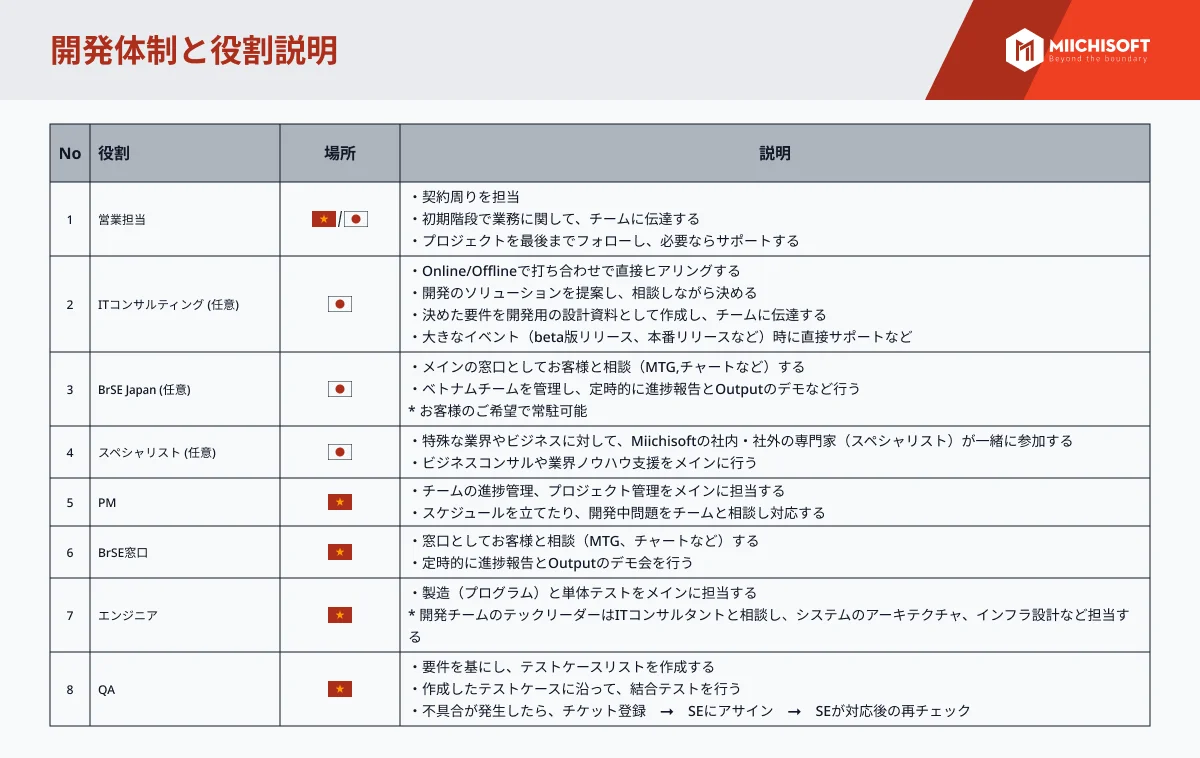
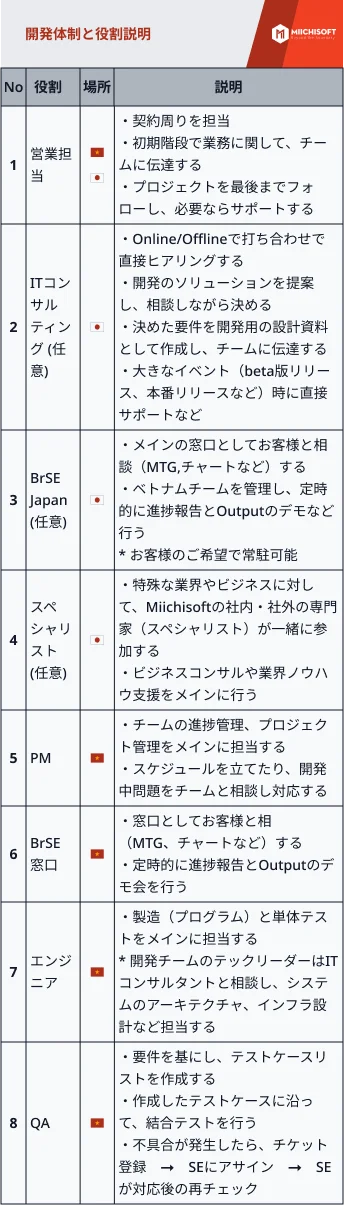
AI駆動のデータ分析が広く利用されているにもかかわらず、多くのデータが未活用のままです。効果的なAI導入にはオープンData Lake Houseアーキテクチャが必要です。データ・レイクハウスの概念は、グローバルな組織がビッグデータの取り扱いにおいて直面する諸課題―具体的にはデータの蓄積量、遅延、可用性、およびデータアクセス要件を適切に管理するためのストレージソリューションを模索する中で生じたものです。データ・レイクハウス・システムは、データウェアハウスおよびデータレイクの双方の利点を最大限に享受しつつ、双方の弱点を排除することを目指す新たなハイブリッドデータアーキテクチャとして登場しました。AIソリューションや最新のテクノロジートレンドを効果的に導入する方法について学びたい方は、この記事をお見逃しなく。Data Lake Houseとは、またデータレイクハウスとAIの組み合わせについて説明し、洞察を提供しています。

1. Data Lake Houseとは
1.1. Data Lake Houseについて
データ・レイクハウスは、データレイク(元の形式の生データの大規模なリポジトリ)とデータウェアハウス(組織化された構造化データのセット)の主要な利点を組み合わせ、単一のプラットフォームを構築する最新のデータアーキテクチャです。特定のデータ・レイクハウスを活用することで、組織は低コストのストレージを使用して大量の生データを保存し、同時に構造とデータ管理機能を提供できるようになります。

これまでにおいて、データウェアハウスとデータレイクは、基盤となるシステムにおける過負荷や同じリソースへの競合の発生を避けるために、それぞれ個別にサイロ化されたアーキテクチャとして実装される必要がありました。企業はデータウェアハウスを通じてビジネスインテリジェンス(BI)およびレポート用の構造化データを保存し、一方でデータレイクを使用して機械学習(ML)ワークロード用の非構造化データおよび半構造化データを蓄積します。しかしこのアプローチでは、どちらかのアーキテクチャのデータを一緒に処理する場合、2つの異なるシステム間でデータを定期的に移動させる必要があり、これが複難さ、コストの増加、そしてデータの新鮮さ、重複、一貫性に関する問題を引き起こすことがあります。Data Lake Houseは、これらのサイロを解消し、データが効率的にビジネス価値を生み出すために必要な柔軟性、拡張性、俊敏性を提供することを目指しています。
Databricks Lakehouse Platform や Amazon Redshift Spectrum など、既存のデータ・レイクハウスの例がいくつかあります。 しかしながら、テクノロジーが進化し続け、データ・レイクハウスの採用が増加するにつれて、実装はレイクハウス コンポーネントを特定のデータ・レイクに結合することから移行してきました。
1.2. データ・レイクハウスとAI目標の達成
効果的なAI導入には、オープンデータレイクハウスアーキテクチャが必要です。なぜなら、データレイクハウスモデルは、データウェアハウスの性能とデータレイクの柔軟性を組み合わせ、今日の複雑なデータの環境に対処し、効果的にAIをスケーリングするからです。
オープンデータレイクハウスアーキテクチャは、新しいデータと既存のデータを組み合わせることで、AIをサポートします。Data Lake Houseアプローチは、共有のメタデータレイヤーを提供し、オープンデータフォーマットをサポートすることで、組織が分析とAIプロジェクトを信頼性高く実行できます。
データとAIの影響のスケールに備えるためには、オープンデータレイクハウスアプローチの採用が重要です。オープンデータレイクハウスアーキテクチャは、すべてのデータソースにわたるAIワークロードのスケーラビリティを提供します。
2. Data Lakehouse vs. Data Lake vs. Data Warehouse
「データ レイクハウス」という語は、データ ウェアハウスおよびデータ レイクといった2つの既存データ・リポジトリを統合した概念であります。では、データ レイクハウスとデータ レイクとデータウェアハウスの差異は具体的に何でしょうか。

2.1. データウェアハウス
データ ウェアハウスは、意思決定のためのレポートや洞察を生成する必要があるビジネスユーザーに、データへの迅速なアクセスとSQL互換性を提供します。全てのデータはETL(抽出、変換、ロード)フェーズを経る必要があり、これにより、ユースケースに基づいて特定のフォーマットやスキーマで最適化され、高パフォーマンスなクエリとデータ整合性をサポートします。ただし、このアプローチではデータへの柔軟なアクセスが制約され、将来の利用に向けてデータを移動する場合に追加のコストが発生します。
2.2. データレイク
データ レイクには、大量の非構造化データと構造化データがネイティブ形式で保存されます。データ ウェアハウスとは異なり、分析中にデータが処理、クリーンアップ、変換されるため、読み込み速度が向上し、ビッグデータ処理、機械学習、予測分析に最適です。ただし、データサイエンスの専門知識が必要であり、データを利用できる人が制約され、データが適切に維持されていない場合、時間の経過とともにデータの品質が低下する可能性があります。また、データ レイクではデータが未処理であるため、リアルタイムクエリの取得がより困難になります。そのため、使用する前にクリーンアップ、処理、取り込み、統合する必要があります。
2.3. Data Lake Houseとは
データ レイクハウスは、これら2つのアプローチを統合し、BIからデータ サイエンス、機械学習まで、多岐にわたる目的でデータにアクセスして活用できる単一の構造を構築します。要するに、データ レイクハウスは、組織の非構造化データ、構造化データ、および半構造化データをすべて収集して低コストのストレージに保存し、全てのユーザーが必要に応じてデータを整理および探索できる機能を提供します。
これらのメリットを1つのデータアーキテクチャで統一することで、データチームは機械学習などの高度な分析を実施し、拡張するために2つの異なるデータシステムにまたがる必要がなくなり、データ処理を効果的に高速化できます。
3. データ レイクハウスの構成要素・機能
3.1. データ レイクハウス アーキテクチャの構成要素
データ レイクハウス アーキテクチャは、以下の各層で構築されています。
3.1.1. ストレージ レイヤー
ストレージ レイヤーは、生データを保存するデータ レイク レイヤーであり、通常は非構造化、構造化、および半構造化データセット向けの低コストのオブジェクト ストアとなります。 コンピューティング リソースから独立しており、これによりコンピューティングを独立して拡張できます。
3.1.2. ステージング レイヤー
ステージング レイヤーは、データ レイク レイヤーの上に位置するメタデータ レイヤーです。 ストレージ内のすべてのデータ オブジェクトに関する詳細なカタログを提供し、スキーマの適用、ACID プロパティ、インデックスの作成、キャッシュ、アクセス制御などのデータ管理機能を適用できるようにします。
3.1.3.セマンティック レイヤー
セマンティック レイヤーであるレイクハウス レイヤーは、すべてのデータを公開して利用可能にします。ユーザーはクライアント アプリや分析ツールを使用して、データにアクセスし、実験やビジネス インテリジェンスのプレゼンテーションにデータを活用できます。
3.2. データ レイクハウスの機能
データ レイクハウスを機能させる際には、まず、データ レイクハウスがどのような目的を達成しようとしているのかを考慮することが肝要です。データ レイクハウスは、組織内の全ての利用者がデータ ユーザーになることを可能にし、異種のデータ ソースを一元管理し、エンジニアリング作業を簡素化することを目指しています。

データ レイクハウスは、データ レイクと同じ低コストのクラウド オブジェクト ストレージを使用し、オンデマンドでのストレージのプロビジョニングとスケーリングを容易にする機能を提供します。データ レイクと同様に、未加工の形式であらゆる種類のデータを大量にキャプチャして保存できます。レイクハウスは、このストア上にメタデータ レイヤーを統合し、構造化スキーマ、ACID トランザクションのサポート、データ ガバナンス、その他のデータ管理および最適化機能など、データウェアハウスのような機能を提供します。
データ レイクハウスの主な機能には次のものがあります。
- すべてのデータ タイプ(構造化、非構造化、半構造化)に対応する単一データの低コスト データ ストア
- スキーマの適用、データ ガバナンスの強化、ETL プロセスとデータ クレンジングを提供するデータ管理機能
- ACID(アトミック性、一貫性、分離性、耐久性)プロパティのトランザクション サポートにより、複数のユーザーが同時にデータの読み取りと書き込みを行う場合にデータの一貫性を確保できます。
- 多くのソフトウェア プログラムで使用できる標準化されたストレージ形式
- リアルタイムのデータ取り込みと洞察生成をサポートするエンドツーエンドのストリーミング
- コンピューティング リソースとストレージ リソースを分離して、さまざまなワークロードのスケーラビリティを確保
4. データ レイクハウスの利点
4.1. 簡素化されたアーキテクチャ
データ レイクハウスは、二つの独立したプラットフォームのサイロを解消することにより、管理と保守に単一のデータ リポジトリへの専念が必要です。ツールはソースデータに直接接続可能であり、データ ウェアハウスでのデータの抽出や準備が不要です。
4.2. データ品質の向上
データ レイクハウスのアーキテクチャでは、構造化データとデータの整合性のスキーマを強制することで、一貫性を確保できます。さらに、レイクハウスは新しいデータの利用可能な時間を短縮し、より新しいデータを確保します。
4.3. コスト削減
大容量のデータを低コストのストレージに保存し、データ ウェアハウスとデータ レイクの維持が不要となります。データ レイクハウスは、ETLプロセスと重複排除によるコスト削減にも寄与します。
4.4. 信頼性の向上
データ レイクハウスは、複数のシステム間のETLデータ転送を削減し、データの移動に伴う品質または技術的な問題の発生可能性を低減します。
4.5 データガバナンスの向上
データとリソースがデータ レイクハウスを使用して1か所に統合されるため、ガバナンスとセキュリティの制御の実装、テスト、提供が容易になります。
4.6.データの重複削減
異なるシステムに存在するデータのコピーが増えると、データの一貫性が損なわれ、信頼性が低下する可能性が高まります。データ レイクハウスを使用すると、ビジネス全体で共有可能な単一のデータソースを実現し、データの重複による不整合や追加のストレージコストを防ぐことができます。
4.7. 多様なワークロード
複数のツールをレイクハウスに直接接続して、同じリポジトリから分析、SQL、機械学習、データサイエンスのワークロードをサポートできます。
4.8. 高い拡張性
データ レイクハウスの低コストのクラウドオブジェクトストレージを使用すると、コンピューティングをストレージからほぼ無制限に分離し、即時のスケーラビリティを提供できます。ビジネスのニーズに応じて、コンピューティング能力とストレージを個別に拡張できます。
5. データ レイクハウス使用の課題
データ レイクハウスの概念はまだ比較的新しいアーキテクチャであり、最大の課題の一つはは、データ レイクハウスが進化しており、ベスト プラクティスがまだ初期採用者によって定義されているという事実に対処することを意味します。さらに、データ レイクハウスを一から構築するのは複雑であり、ほとんどの場合、すぐに使えるデータ レイクハウス ソリューションを選択するか、Google Cloudなどのプラットフォームが提供するオープン レイクハウス アーキテクチャをサポートするために必要なすべてのコンポーネントを取得する必要があります。
6. FAQ
問1: Data Lake Houseとは何ですか?
Data Lake Houseとは、データレイクとデータウェアハウスの間の隔たりをなくします。、大量の異種のデータを効果的に蓄積、統合、管理するためのアーキテクチャです。これは、構造化および非構造化のデータを一元化して取り扱うことが可能で、企業のデータ管理に革新をもたらしています。
問2: Data Lake Houseのアプローチは、AIの目標をどのようにサポートしますか?
Data Lake Houseのアプローチは、膨大なデータセットへのアクセスを容易にし、AIモデルのトレーニングおよび開発を向上させます。これにより、より正確で洗練された人工知能の構築が可能となり、ビジネス目標の達成に寄与します。
問3: データ・レイクハウスが他のデータ管理アプローチと比較して優れている点は何ですか?
データレイクハウスは、データレイクとデータウェアハウスの間の隔たりをなくします。つまり、データレイクの低コストで柔軟なストレージを介してデータをデータウェアハウスに容易に移行でき、データクレンジングのために機械学習と人工知能を活用したスキーマとガバナンスを実装するデータウェアハウスの管理ツールに容易にアクセスできます。その結果、データレイクの非構造化で手ごろなコレクションと、データウェアハウスの頑丈な準備を統合したデータリポジトリが形成されます。データレイクハウスは、キュレーションされたデータソースから収集する領域を提供し、ビジネス向けにデータを整備するツールや機能を用いて、プロセスを迅速に進めます。
つまり、データ・レイクハウスは、柔軟性と拡張性に優れ、異種のデータを統合する能力があります。これにより、変化するビジネスニーズに対応し、リアルタイムでのデータ分析を可能にします。
7. まとめ
総括すると、Data Lake Houseは、従来のデータウェアハウスとデータレイクの利点を巧みに融合させた、現代のデータ管理の最前線に立つ存在です。この革新的なアーキテクチャは、多様なデータ型を効率的に格納し、管理し、分析するための統合されたプラットフォームを組織に提供します。データシロの課題に対処し、拡張性、柔軟性、リアルタイム分析を提供することで、Data Lake Houseは変革的なソリューションとして浮上しています。協力を促進し、データ品質を確保し、アジャイルな意思決定をサポートするその能力は、現代のAI・デジタルランドスケープでデータ資産のフルポテンシャルを引き出すための鍵と位置付けられます。
Miichisoftは、数多くの日本のお客様がビジネス上の課題に効果的に対処できるように支援してきた、高度な資格を持つ開発者チームを擁するテクノロジー会社です。Data Warehouse、Data Lake、Data Lakehouseのテクノロジーを活用したソリューションの開発に豊富な経験を有しています。ビジネスデータに関する問題にお心当たりがあれば、どうぞMiichisoftの無料相談をご利用ください。