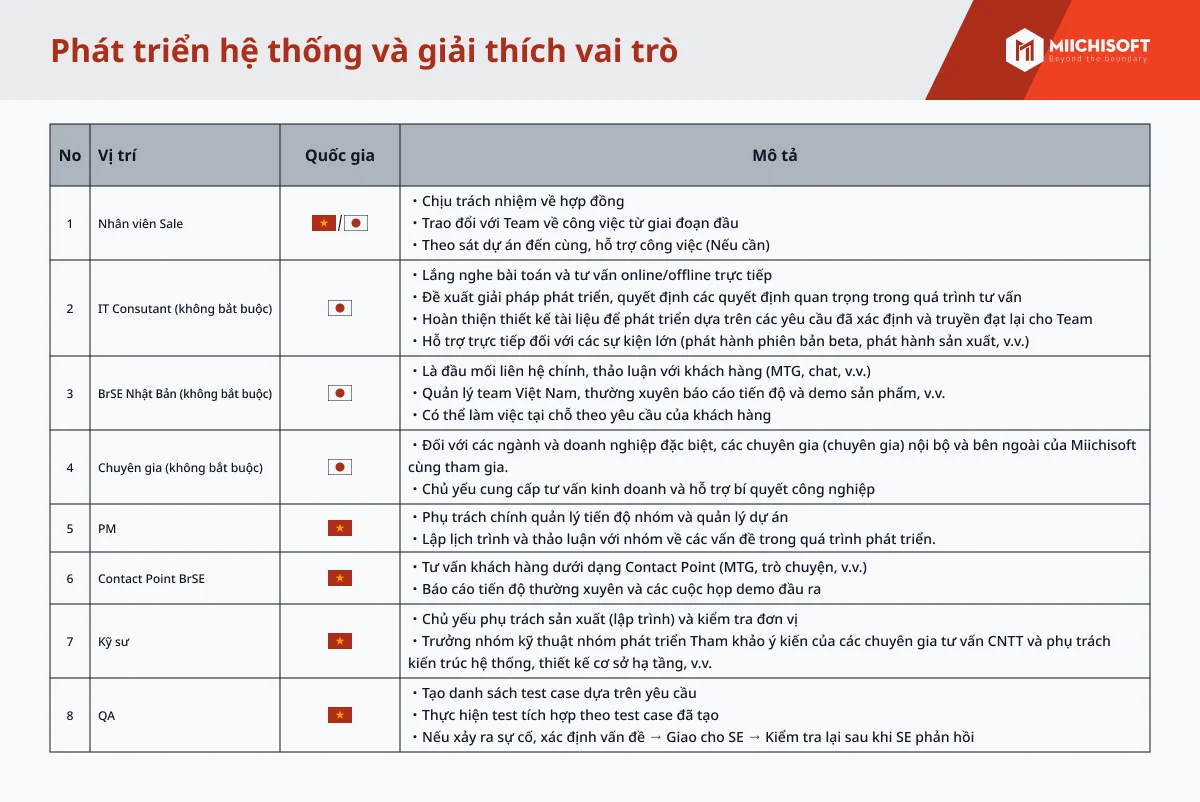
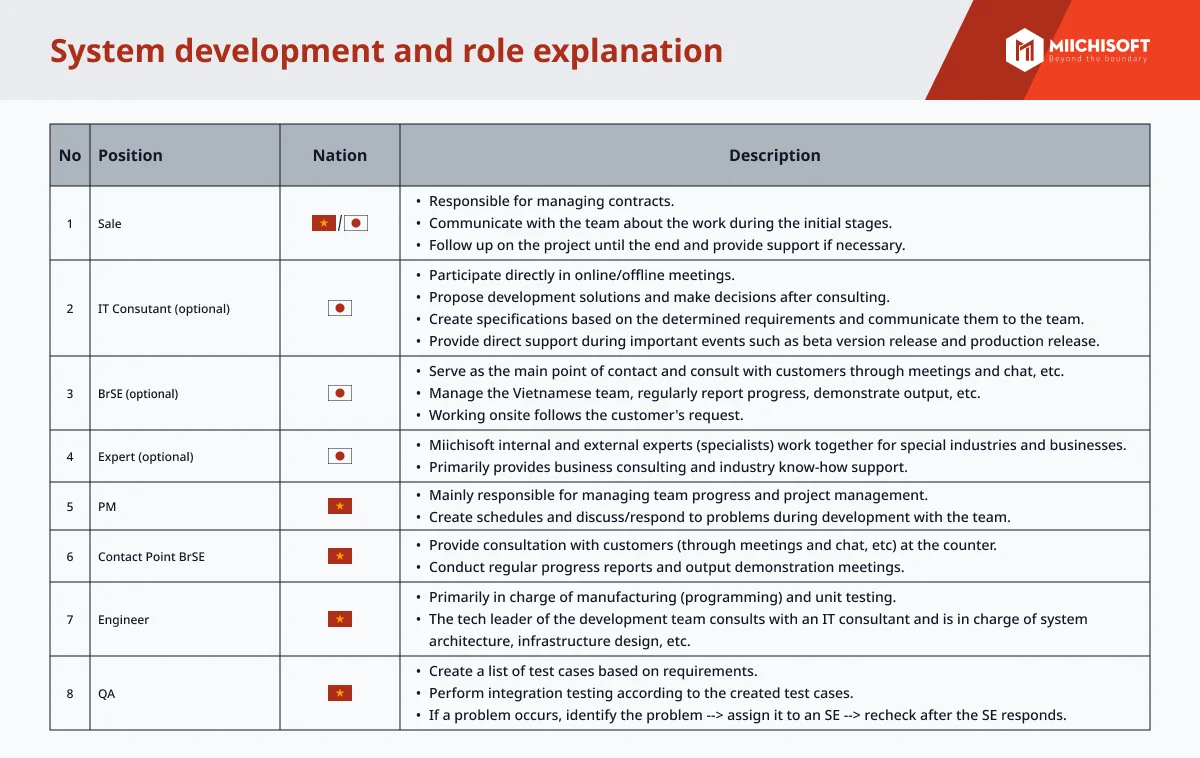
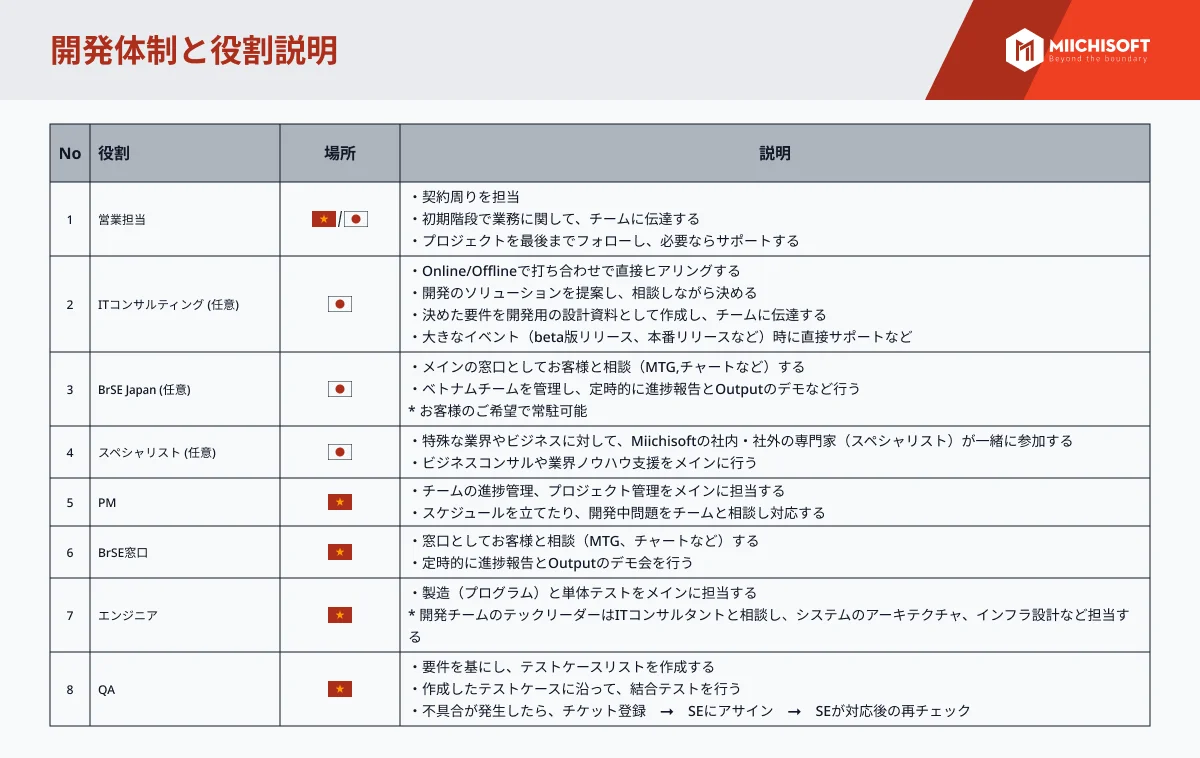
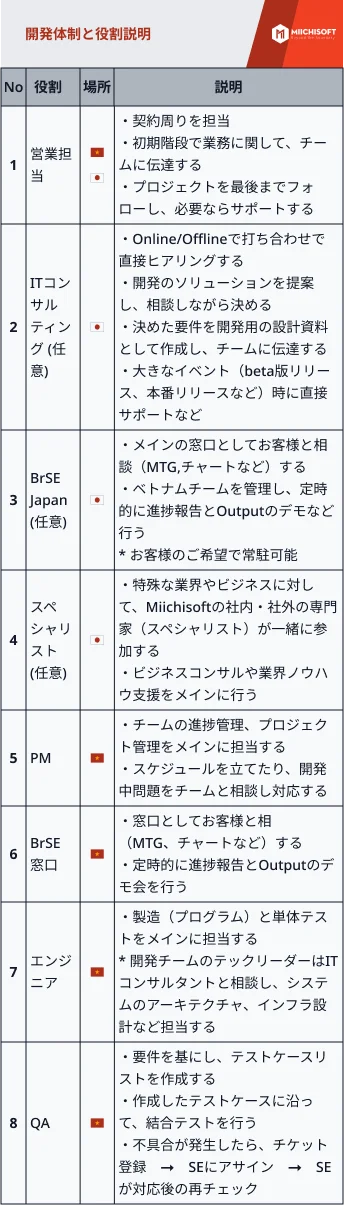
システムのパフォーマンスを改良する5つの方法-1.png?ver=1712206924)
LLM(Large Language Models)は素晴らしい発明ですが、1つの重要な問題が発生する傾向があります。AI幻覚に悩まされることがあります。 RAG(Retrieval Augmented Generation)は、この問題に対処するために開発され、クエリに応答する際に使用する事実に基づいたコンテキストをLLMに提供することで、LLMをさらに便利にします。
本記事では、ユーザーの問い合わせに対する質の高い回答を生成するために、大規模言語モデル(LLM)を使用するRetrieval Augmented Generation(RAG)システムのパフォーマンスを向上させる方法について解説します。RAGシステムは外部情報を活用してLLMによる回答を強化するもので、本稿ではその有効性を高める6つの実践的な戦略に焦点を当てています。
1. Retrieval-Augmented Generation(RAG)クイックスタートガイド
システムのパフォーマンスを改良する6つの方法 1")
RAG(検索拡張生成)は、ユーザーの入力を大規模な言語モデル(LLM)例えばChatGPTに、別の場所から取得した追加情報で補完するプロセスです。その情報をLLMは使用して、生成される応答を補完します。
この記事では、RAGシステムの品質向上に焦点を当て、そのための戦略を詳細に調査します。 RAGを使用して構築されたユーザー向けに、基本的なセットアップと運用レベルのパフォーマンスの間に存在するギャップを埋めたいと考えています。 この記事の目的は、改善とは、システムが次のことを行うクエリの割合を増やすことを意味します。具体的には、
- 適切なコンテキストの検出
- 適切な応答の生成
RAGの仕組みについてさらに詳しく知りたい場合は、この記事をお読みいただくことをお勧めします。
2. RAG(検索拡張生成)のパフォーマンスを改良する6つの方法
ここでは、取り上げる各戦略の具体的な実装方法については詳しく説明しませんが、代わりにそれがいつ、なぜ役立つのかについて説明します。 空間の移り変わりの速さを考えると、網羅的または完全に最新のベストプラクティスのリストを提供することは不可能です。 その代わりに、検索拡張生成アプリケーションを改善しようとするときに検討および試行できるいくつかのことを概説することを目的としています。
2.1. データの整理と清掃
RAGは、LLMの機能をデータに連結させるプロセスです。 データの内容やレイアウトが混乱している場合、システムに問題が生じます。 矛盾する情報や冗長な情報を含むデータを使用している場合、検索で適切なコンテキストを見つけることが困難になります。 このような場合、LLMによって実行される生成ステップが最適ではない可能性があります。
スタートアップ企業のヘルプドキュメント用のチャットボットを構築していて、それがうまく機能していないことに気付いたとします。 まず最初に確認する必要があるのは、システムに入力しているデータです。 トピックは論理的に分割されていますか? トピックは1か所で扱われますか、それとも複数の別々の場所で扱われますか? 人間として、一般的なクエリに答えるためにどの文書を見ればよいのかを簡単に判断できない場合、検索システムもそれを判断できません。
このプロセスは、同じトピックに関するドキュメントを手動で結合するのと同じくらい簡単ですが、さらに進めることもできます。 私がこれまでに見たよりも創造的なアプローチの1つは、LLMを使用して、提供される全てのドキュメントの概要を作成することです。 取得ステップでは、まずこれらの概要に対して検索を実行し、必要な場合にのみ詳細を調べます。 一部のフレームワークには、これが組み込まれた抽象化として提供されている場合もあります。
2.2. さまざまな種類のインデックス
インデックスは、LlamaIndexとLangChainの中核を成す要素です。これは、検索システムを保持するオブジェクトです。 RAGへの標準的なアプローチには、埋め込みと類似性検索が含まれます。 コンテキストデータを分割して全体を埋め込み、クエリが発生したときにコンテキストから類似した部分を見つけます。 これは非常に効果的ですが、あらゆるユースケースに最適なアプローチとは言えません。 クエリは、例えば電子商取引ストアの商品など、特定のアイテムに関連するものですか? キーワードベースの検索を検討すると良いでしょう。 どちらか一方である必要はありません。多くのアプリケーションはハイブリッドを使用しています。 たとえば、特定の製品に関連するクエリにはキーワードベースのインデックスを使用しますが、一般的なカスタマーサポートには埋め込みを使用することができます。
2.3. 基本プロンプトの試し
システムのパフォーマンスを改良する6つの方法 2")
LlamaIndexで使用される基本プロンプトの一例は以下の通りです。
「コンテキスト情報は以下の通りです。事前知識ではなく、コンテキスト情報を考慮して質問に答えてください。」
これを上書きして、他のオプションを試すことができます。 RAGをハッキングして、コンテキスト内で適切な答えが見つからない場合にLLMが自身の知識に依存できるようにすることもできます。 また、プロンプトを調整して、受け入れるクエリの種類を制御することもできます。 たとえば、主観的な質問に対して特定の方法で応答するように指示することもできます。 少なくとも、LLMが実行中のジョブに関するコンテキストを把握できるようにプロンプトを上書きすると便利です。 例えば:
「あなたはカスタマーサポートエージェントです。 事実に基づく情報のみを提供しながら、可能な限り役立つように設計されています。 フレンドリーである必要がありますが、おしゃべりになりすぎないようにしてください。 コンテキスト情報は以下のとおりです。 事前知識ではなく、コンテキスト情報を考慮して質問に答えてください。」
2.4. クエリルーティングの使用
システムのパフォーマンスを改良する6つの方法 3")
多くの場合、複数のインデックスがあると便利です。 次に、クエリが到着したときに、適切なインデックスにクエリをルーティングします。たとえば、要約質問を処理するインデックス、具体的な質問を処理するインデックス、および日付に依存する質問に適したインデックスを別のインデックスに割り当てることができます。 これらすべての動作に対して1つのインデックスを最適化しようとすると、すべての動作のパフォーマンスが損なわれることになります。 代わりに、クエリを適切なインデックスにルーティングできます。 別の使用例は、一部のクエリをキーワードベースのインデックスに送信することです。
インデックスを作成したら、それぞれを何に使用するかをテキストで定義するだけです。 その後、クエリ時にLLMが適切なオプションを選択します。 LlamaIndexとLangChainの両方には、これのためのツールがあります。
2.5. クエリ変換の検討について
ユーザーのクエリは、既にベースプロンプト内に配置することで変更されています。 それをさらに変更することは理にかなっています。 以下には、いくつかの例があります。
言い換え: システムがクエリに関連するコンテキストを見つけられない場合は、LLMにクエリを言い換えて再試行させることができます。 人間にとって同じように見える2つの質問は、埋め込み空間では必ずしも同じように見えるとは限りません。
HyDE: HyDEは、クエリを受け取り、仮説的な応答を生成し、その両方を埋め込み検索に使用する戦略です。 研究により、これによりパフォーマンスが劇的に向上することがわかっています。
サブクエリ: LLMは、複雑なクエリを分解するとより適切に機能する傾向があります。 これをRAGシステムに組み込んで、クエリを複数の質問に分解することができます。
2.6. 埋め込みモデルの微調整
埋め込みベースの類似性は、RAGの標準の検索メカニズムです。 データは分割され、インデックス内に埋め込まれます。 クエリが入力されると、インデックス内の埋め込みと比較するためにクエリも埋め込まれます。 しかし、埋め込みとは何でしょうか? 通常、OpenAIのtext-embedding-ada-002などの事前トレーニング済みモデル。
問題は、埋め込み空間で何が類似しているかという事前トレーニング済みモデルの概念が、コンテキストでの類似点とあまり一致しない可能性があることです。 法的文書を扱っていると想像してください。 埋め込みの類似性の判断の基準を、「ここに」や「同意」などの一般的な用語ではなく、「知的財産」や「契約違反」などのドメイン固有の用語に基づいて決定したいと考えています。
埋め込みモデルを微調整して、この問題を解決できます。 そうすることで、取得メトリクスを5~10%向上させることができます。 これにはもう少し手間がかかりますが、検索パフォーマンスに大きな違いが生じる可能性があります。 LlamaIndexはトレーニングセットの生成に役立つため、このプロセスは思ったよりも簡単です。
3. よくある質問(FAQ)
質問1: RAG(Retrieval Augmented Generation)とは何ですか?
回答: RAGは、ユーザーのクエリに応答するために外部から取得した情報を使い、その情報をベースに大規模な言語モデル(LLM)が応答を生成するプロセスです。これにより、AIが発する幻覚を減らし、より事実ベースの回答を提供することができるようになります。
質問2: データの整理と清掃はRAGシステムにとってなぜ重要なのですか?
回答: データの内容やレイアウトが整っていないと、検索エンジンが適切なコンテキストを見つけるのが難しくなり、結果として生成される応答の品質が低下します。整理されており一貫性のあるデータは、検索精度を高め、より関連性の高い情報を抽出するのに役立ちます。
質問3: クエリルーティングとはどのようなものですか?
回答: クエリルーティングは、受け取ったクエリを最も適切なインデックスに自動的に送るプロセスです。これにより、異なるタイプの質問に対してより専門化された応答を生成することが可能になります。
質問4: 埋め込みモデルを微調整することのメリットは何ですか?
回答: 埋め込みモデルを微調整することで、モデルが特定の領域のデータにより適した埋め込み表現を学習することができます。これは、検索結果の関連性と精度を高め、検索拡張生成の全体的なパフォーマンスを改善します。
4. 結論
RAGを使用して構築すると、作業を開始するのは非常に簡単ですが、うまく機能させるのが非常に難しいため、イライラすることがあります。 上記の戦略が、ギャップを埋める方法についてのヒントになれば幸いです。 これらのアイデアのどれも常に機能するわけではなく、そのプロセスは実験、試行錯誤の1つです。 この記事では、システムのパフォーマンスを測定する方法である評価については詳しく説明しませんでした。 現時点では評価は科学というより芸術のようなものですが、常にチェックインできる何らかのシステムをセットアップすることが重要です。 これが、実装している変更が変化をもたらすかどうかを知る唯一の方法です。
Miichisoftは、RAGテクノロジーを活用したソリューションの開発に豊富な経験を有しています。RAGの仕組みについて詳細については、当社のウェブサイトのこの記事をご覧ください。