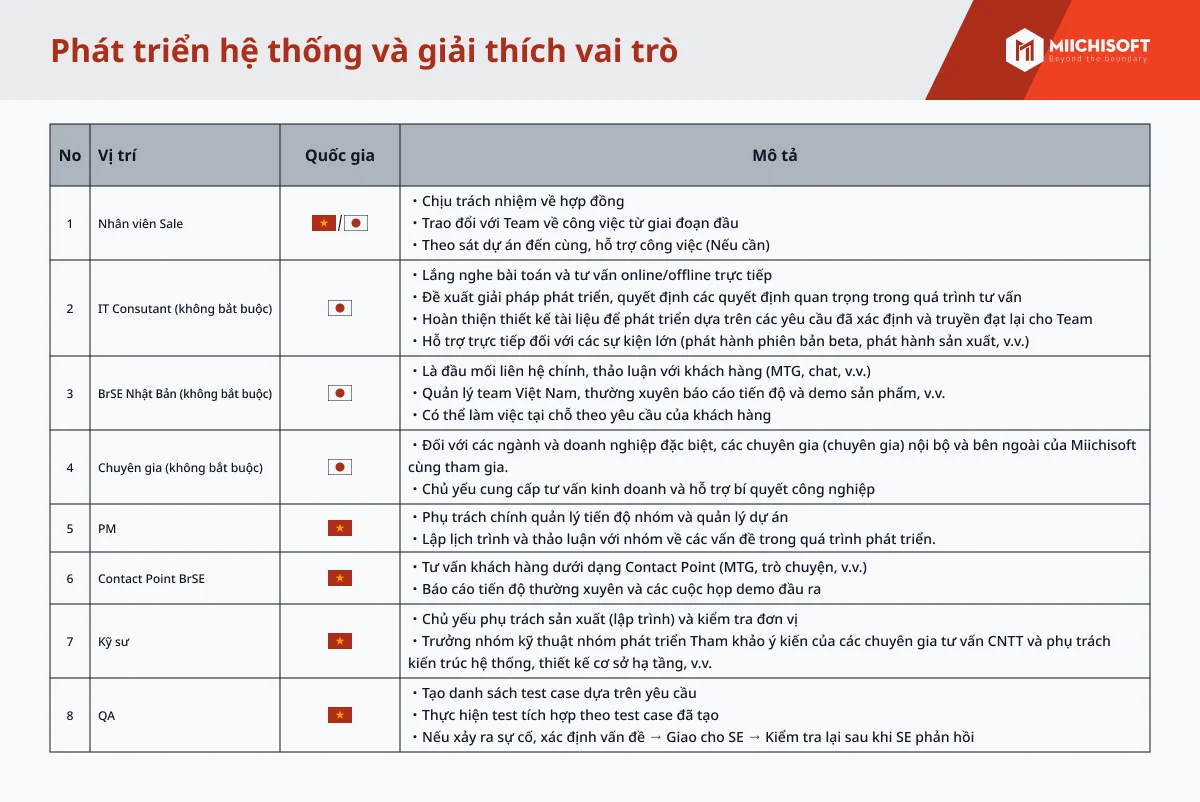
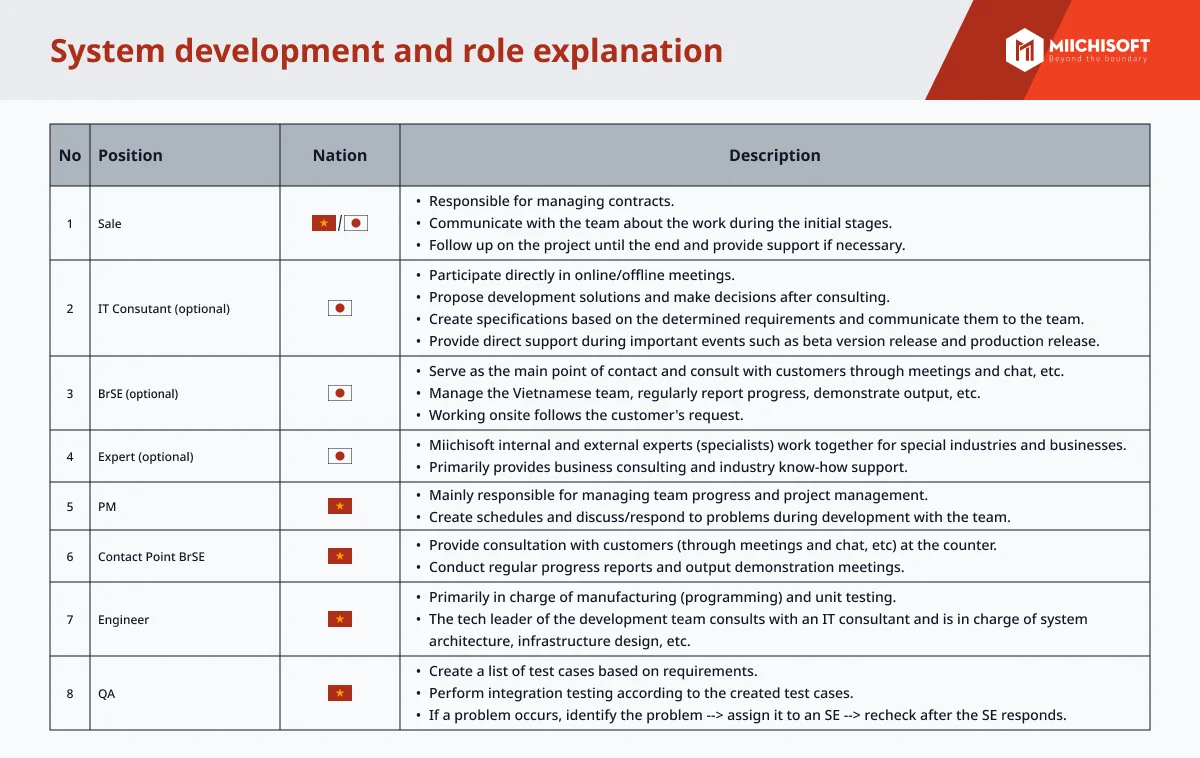
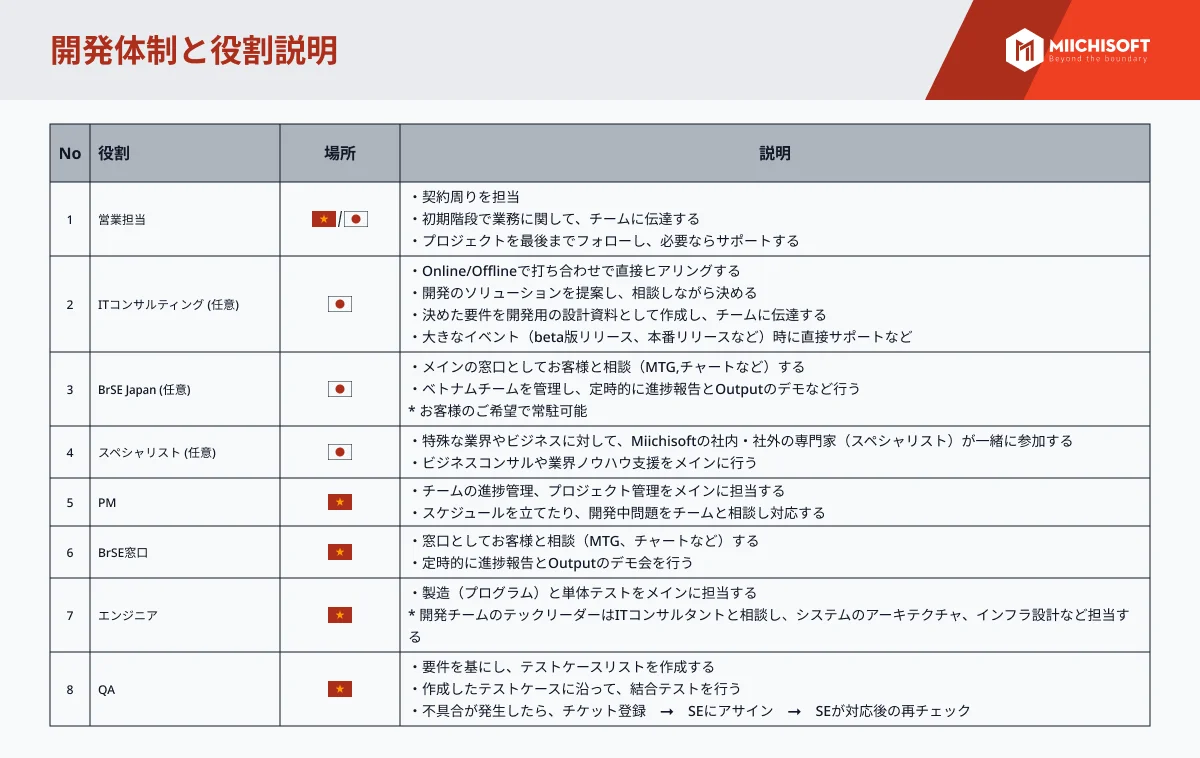
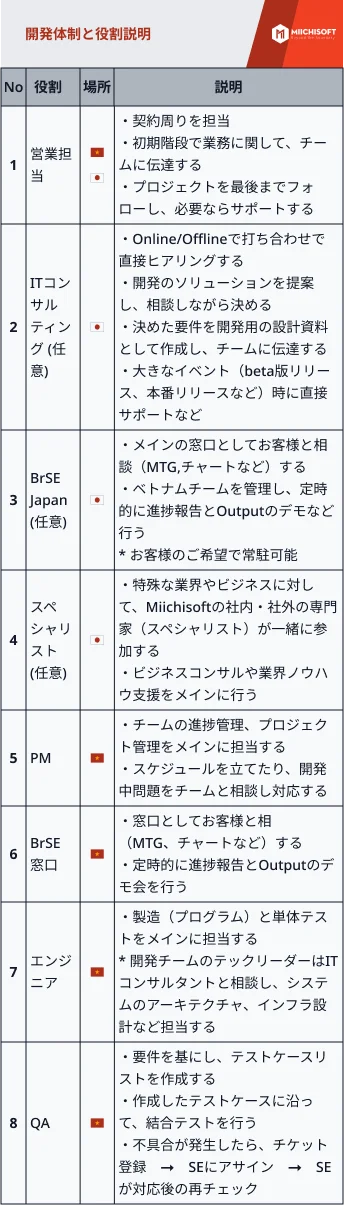
企業のデジタル変革の必要性に高まる中で、経営幹部は人工知能 (AI) と機械学習をますます採用するようになっています。 しかし、AI の可能性と現実世界の成功の間には顕著なギャップがあり、データ管理における根本的な問題が明らかになりました。 AIの進化には基本に戻る必要があります:データです。アルゴリズムと計算能力は重要ですが、AIの成功には適切なデータ管理、ガバナンス、およびオーケストレーションが基盤となります。幸いなことに、データプラットフォームの進化により、企業はますます複雑なデータエコシステムに取り組む手助けができるようになっています。データ プラットフォーム、特にデータ レイクハウスの進歩により、複雑なデータ エコシステムをナビゲートするためのソリューションが提供されていますが、注意点もあります。
Data Warehouse、Data Lake、Data Lake Houseとは、ビッグデータストレージの主要なパターンとして広く利用されています。各パターンには独自の特徴があり、ビジネスのニーズに応じて選択できる多様なオプションがあります。本記事は、Data Warehouse・Data Lake・Data Lake Houseの3つのクラウドデータストレージパターンの比較について説明します。

1. データウェアハウス
1.1. データウェアハウスとは
データウェアハウスは、組織内の複数のソースからの大量の情報を統合的に保存するためのデータリポジトリです。データウェアハウスは、組織内の「データの真実」を単一のソースで表現し、中核的なレポートおよびビジネス分析のコンポーネントとして機能します。
通常、データウェアハウスは、アプリケーションデータ、ビジネスデータ、トランザクションデータなど、複数のソースからのリレーショナルデータセットを組み合わせ履歴データを保存します。データウェアハウスは、データを抽出し、ウェアハウスシステムにロードする前にデータを変換およびクリーンアップして、真実のデータの単一のソースとして機能します。組織がデータウェアハウスに投資する理由は、組織全体で迅速にビジネスに関する洞察を提供できるからです。

データウェアハウスを使用することで、ビジネスアナリスト、データエンジニア、意思決定者は、BIツール、SQLクライアント、その他の高度ではない(データサイエンス以外の)分析アプリケーションを介してデータにアクセスできます。
1.2. データウェアハウスの利点
データウェアハウスの導入により、組織は著しいメリットを享受できます。以下に、これに伴う利点が示されています。
- データの標準化、品質、一貫性の向上: 組織は販売データ、ユーザーデータ、トランザクションデータなど、多岐にわたるソースからデータを生成しています。データウェアハウスは企業データを統合し、一貫性のある標準化された形式に変換することで、単一の情報源としての機能を果たし、組織はビジネスニーズに適応した信頼性の高いデータを得ることができます。
- 強化されたビジネスインテリジェンスの提供: データウェアハウスは、実務上自動的に収集される大量の生データと、洞察を提供するために厳選されたデータの間に生じるギャップを埋めます。これらは組織のデータストレージの基盤として機能し、複雑なデータに関する問いに答え、その情報を活用して基づくビジネス上の意思決定を行うことができます。
- データ分析とビジネスインテリジェンスのワークロードの能力と速度の向上: データウェアハウスは、データの準備と分析に要する時間を短縮します。データウェアハウス内のデータは一貫性があり正確であるため、データ分析やビジネスインテリジェンスツールに簡単に接続できます。また、データウェアハウスはデータ収集に必要な時間を削減し、チームがレポート、ダッシュボード、およびその他の分析ニーズにデータを活用できるようにします。
- 全体的な意思決定プロセスの改善: データウェアハウスは、現在および過去のデータの単一リポジトリを提供することで、意思決定を改善します。意思決定者はデータウェアハウス内のデータを変換して正確な洞察を得ることで、リスクを評価し、顧客のニーズを理解し、製品とサービスを改善できます。
例えば、Walgreensは在庫管理データをAzure Synapseに移行し、サプライチェーンアナリストがMicrosoft Power BIなどのツールを使用してデータをクエリし、視覚化を行うことができるようにしました。クラウドデータウェアハウスへの移行により、洞察を得るまでの時間も短縮され、前日のレポートは数時間ではなく、営業日の開始時に利用できるようになりました。
1.3. データウェアハウスの課題
データウェアハウスは、高性能かつスケーラブルな分析をビジネスに提供しますが、これには特有の課題が伴います。それらを以下に示します。
データの柔軟性の不足: データウェアハウスは、構造化データに対しては効果的ですが、ログ分析、ストリーミング、ソーシャルメディアデータなどの半構造化および非構造化データ形式においては限定的な機能しか発揮しません。従って、機械学習や人工知能のユースケースにおいてデータウェアハウスを推奨することは困難です。
高い実装コストと保守コスト: データウェアハウスの実装および保守には相応の経費がかかり得ます。Cooladataによると、1テラバイトのストレージおよび月間10万回のクエリを処理可能な社内データウェアハウスの年間コストは約468,000ドルに見積もられています。加えて、データウェアハウスは通常、静的ではなく、経時的なメンテナンスが必要となるため、追加の費用が発生することがあります。
2.データレイク
2.1. データレイクとは
データレイクとは何かについての簡潔な説明を行います。データレイクは、膨大な構造化データおよび非構造化データを生の、元の、フォーマットされていない形式で集中的かつ柔軟性の高いストレージリポジトリに保存するものです。これは、既存の「クリーン化された」リレーショナルデータを保存するデータウェアハウスとは対照的であり、データレイクはフラットアーキテクチャとオブジェクトストレージを駆使してデータを生の形式で保管します。データレイクはその柔軟性、耐久性、およびコスト効率において優れており、これによりデータウェアハウスが苦労するような非構造化データからの高度な洞察を組織は得ることが可能です。
データレイクの特徴として、データがキャプチャされる瞬間においてはスキーマやデータが事前に定義されません。代わりに、データは分析目的で抽出、ロード、変換(ELT)されます。このデータレイクにより、IoTデバイス、ソーシャルメディア、ストリーミングデータなどの様々なデータタイプに対応するツールを活用し、機械学習と予測分析が可能になります。

2.2. データレイクの利点
データレイクは、構造化データと非構造化データの両方を格納可能であり、これによりいくつかの利点が生じます。
- データの統合: データレイクが構造化データと非構造化データの双方を格納できるため、これにより異なる環境においてそれぞれのデータ形式を保存する必要がなくなります。データレイクはあらゆる組織データを一元的に保管するための中央リポジトリを提供します。
- データの柔軟性: データレイクの大きな利点はその柔軟性にあります。予め定義されたスキーマが不要であり、任意の形式や媒体でデータを保存できます。データをネイティブ形式のまま保持することで、より多くのデータを分析し、将来のデータユースケースに対応することが可能となります。
- コスト削減: データレイクは従来のデータウェアハウスよりも経済的です。これらは通常、低コストの汎用ハードウェア(例:Amazon S3標準オブジェクトストレージなど)にデータを格納するように設計され、保存コストは通常、GBあたりのコストが低くなるように最適化されています。
さまざまなデータサイエンスと機械学習のユースケースのサポート: データレイク内のデータはオープンな生の形式で保持されるため、様々な機械学習アルゴリズムやディープラーニングアルゴリズムを適用しやすく、意味ある洞察を得ることが容易となります。
2.3. データレイクの課題
データレイクには多くの利点がありますが、以下に示す課題も存在します。
- ビジネスインテリジェンスとデータ分析のユースケースでのパフォーマンスの低下: 適切に管理されていない場合、データレイクが組織化されず、ビジネスインテリジェンスや分析ツールとの連携が困難になる可能性があります。また、一貫したデータ構造とACIDトランザクションサポートが不足していると、レポートや分析のユースケースで必要な場合にクエリのパフォーマンスが最適化されない可能性があります。
- データの信頼性とセキュリティの不足: データレイクはデータの一貫性が不足しているため、データの信頼性とセキュリティを向上させることが難しくなります。データレイクはすべてのデータ形式に対応できるため、機密データの適切なデータセキュリティとガバナンスポリシーを実装することが困難な場合があります。
3. Data Lake Houseとは:融合したアプローチ
3.1. Data Lake Houseとは
データ・レイクハウスとは、新たなビッグデータ・ストレージ・アーキテクチャであり、データ・ウェアハウスとデータ・レイクの最適な特性を融合させたものです。このアプローチにより、データ・レイクハウスはクラス最高の機械学習、ビジネス・インテリジェンス、およびストリーミング機能を実現し、構造化、半構造化、非構造化のあらゆるデータを単一のリポジトリで効果的に管理できます。
通常、データ・レイクハウスは全てのデータ型を含むデータ・レイクとして初めて展開されます。その後、データはDelta Lake形式へ変換され、オープンソースのストレージ・レイヤーであるDelta Lakeにより、データ・レイク上でACIDトランザクション処理が可能になります。
3.2. データ・レイクハウスの利点
データ・レイクハウスのアーキテクチャは、データ・ウェアハウスのデータ構造と管理機能を、データ・レイクの低コストのストレージと柔軟性と組み合わせています。この実装の利点は非常に大きく、以下に挙げるようなものがあります。
- データの冗長性の削減: データ・レイクハウスは、あらゆるビジネスデータの需要に応える単一の汎用データ・ストレージ・プラットフォームを提供することで、データの重複を削減します。データ・ウェアハウスとデータ・レイクはそれぞれ利点がありますが、ほとんどの企業はハイブリッド・ソリューションを選択します。ただし、このアプローチではデータの重複が発生し、コストがかかる可能性があります。
- 費用対効果: データ・レイクハウスは、低コストのオブジェクト・ストレージ・オプションを利用して、データ・レイクの費用対効果の高いストレージ機能を実装します。さらに、データ・レイクハウスは、単一のソリューションを提供することで、複数のデータ・ストレージ・システムを維持するコストと時間を削減します。
- さまざまなワークロードのサポート: データ・レイクハウスは、最も広く使用されているビジネスインテリジェンスツール(Tableau、PowerBI)への直接アクセスを提供し、高度な分析を可能にします。さらに、データ・レイクハウスは、Python/RなどのAPIおよび機械学習ライブラリを備えたオープンデータ形式(Parquetなど)を使用しているため、データサイエンティストや機械学習エンジニアがデータを簡単に利用できるようになります。
- データのバージョン管理、ガバナンス、セキュリティの容易さ: データ・レイクハウスのアーキテクチャにより、スキーマとデータの整合性が強化され、堅牢なデータセキュリティとガバナンスのメカニズムの実装が容易になります。
3.3. データレイクハウスの課題
データレイクハウスの主要な課題は、これがまだ比較的新しく未発展の技術であるという点にあります。そのため、その有望性が果たして実現されるかどうかは不透明です。データレイクハウスが成熟したビッグデータストレージソリューションと競り合えるようになるには、数年かかる可能性があります。ただし、現代のイノベーションの進展速度を考慮すると、新たなデータストレージソリューションが最終的にこれを凌駕するかどうかを予測することは困難です。
3.4. データレイクハウスとAIツール
データレイクハウスは買収およびビルド投資の時折混沌とするデータランドスケープに秩序をもたらすだけでなく、これらの企業を将来のAI分析ツールを活用できるようにも整えています。例えば、Power BIにはQ&A機能があり、MicrosoftがOpenAIのテクノロジーをソフトウェアに組み込むにつれて、その性能が大幅に向上する可能性があります。現在データを統合している企業は、これらの技術の進歩を利用でき、同じことをしていない競合他社に対して優位性を持つかもしれません。
重要な注意:AIを効果的に活用するためには、クリーンな基盤となるデータが必要です。計画を立てる際には、AIに進む前にデータ基本を投資する視点と、CTOアンディ・スコットおよびCIOジョン・マンザナレスとのインタビューをご覧ください。
4. データ ウェアハウス対データ レイク対データ レイクハウス: 概要
データ ウェアハウスは、ビジネスインテリジェンス、レポート、および分析アプリケーションにおいて、長い歴史を誇る最も歴史あるビッグデータストレージテクノロジです。ただし、その高価性と、ストリーミングや非構造化データの多様性などへの対処が困難であるという課題が存在します。
データ レイクは、機械学習やデータサイエンスのワークロードに対応するために登場し、安価なストレージ上でさまざまな形式の生データを処理します。データ レイクは非構造化データを効果的に処理できますが、データ ウェアハウスのACIDトランザクション機能の不在により、データの一貫性と信頼性を確保することが困難になります。
データ レイクハウスは、データ レイクのコスト効率と柔軟性と、データ ウェアハウスの信頼性と一貫性を組み合わせた最新のデータストレージアーキテクチャです。
この表は、データ ウェアハウス、データ レイク、データ レイクハウスの違いを整理したものです。
| データ ウェアハウス | データ レイク | データ レイクハウス |
| ストレージ データ タイプ | 構造化データとうまく連携する | 半構造化データおよび非構造化データと連携する |
| 目的 | データ分析およびビジネスインテリジェンス (BI) のユースケースに最適 | 機械学習 (ML) および人工知能 (AI) のワークロードに最適 |
| コスト | ストレージはコストと時間がかかります | ストレージはコスト効率が高く、高速で柔軟です |
| ACID 準拠 | ACID 準拠の方法でデータを記録し、最高レベルの整合性を確保 | 非 ACID 準拠: 更新と削除は複雑な操作である |
「データ レイクハウス vs データ ウェアハウス vs データ レイク」という議論は現在も続いており、最終的なビッグデータストレージアーキテクチャの選択は、扱うデータの種類、データソース、および関係者によるデータの使用方法に依存します。データ レイクハウスはデータ ウェアハウスとデータ レイクの利点を組み合わせたものであり、既存のデータストレージテクノロジを軽視することは避けるべきです。
5. データ ウェアハウス対データ レイク対データ レイクハウス: 企業に最適な選択肢
データ レイクハウス、データ ウェアハウス、データ レイクの三者において、最適な選択肢は何でしょうか。
データ レイクハウスの新規構築は、複雑な場合があります。おそらく、オープン データ レイクハウス アーキテクチャをサポートするために構築されたプラットフォームが使用されるでしょう。従って、購入を検討する前に、各プラットフォームの異なる機能と実装について十分に調査を行うことが重要です。
データ ウェアハウスは、ビジネス インテリジェンスおよびデータ分析のユースケースに焦点を当てた、成熟した構造化データ ソリューションを求める企業にとって適切な選択肢です。ただし、データ レイクは、非構造化データで機械学習とデータ サイエンスのワークロードを推進する柔軟で低コストのビッグデータ ソリューションを求める組織に適しています。
データ ウェアハウスおよびデータ レイクのアプローチが企業のデータ要件を満たしていない場合、または高度な分析および機械学習の両方のワークロードをデータに実装する方法を模索している場合、データ レイクハウスは合理的な選択と言えるでしょう。
6. FAQ
問1: データ・レイクハウス ( Data Lake House )とは何ですか?
Data Lake Houseとは、最新のデータプラットフォームとして、データレイクとデータウェアハウスを結びつけて構築されています。具体的には、データレイクハウスはデータレイクから非構造化データを柔軟に保管し、同時にデータウェアハウスの管理機能とツールを統合しています。これにより、両方の利点を戦略的かつ大規模なシステムとして有効に利用することが可能です。
問2: AI総合の成功において、なぜこれらの異なるデータストレージパターンが重要なのでしょうか?
AI総合の成功において、異なるデータストレージパターンが重要な役割を果たします。データウェアハウスは構造化データの高速な分析を可能にし、データレイクは多様なデータ形式を柔軟に取り扱います。Data Lake Houseはこれらの利点を結合し、より包括的で効率的なデータ処理を提供します。
問3: データウェアハウスとデータレイクハウスの主な違いは何ですか?
データウェアハウスは主に構造化データを取り扱い、分析に特化しています。一方で、Data Lake Houseは構造化と非構造化データを包括的に処理し、柔軟性と総合性が特徴です。データレイクハウスは両者の利点を兼ね備えています。
問4: これらのデータストレージパターンを組織で導入する際に注意すべきポイントはありますか?
データストレージパターンを導入する際には、まず組織のデータの性質と要件を詳細に理解することが重要です。データの機密性、アクセス制御、および統合性を考慮し、適切なデータストレージパターンを選択する必要があります。また、スケーラビリティやセキュリティの観点からも検討が必要です。
7. まとめ
本記事では、Data Warehouse、Data Lake、Data Lakehouseの比較と、データ管理の微妙な状況について情報を提供します。データウェアハウスは構造化分析に優れ、データレイクは多様なデータに対する柔軟性を提供しますが、Data Lakehouseの登場はこれらの強みを巧みに組み合わせたものです。Data Lakehouseは、トランザクション機能とスキーマの厳格な適用を統合することで、構造化データと非構造化データの間のギャップを埋める統合ソリューションを提供しています。どのアーキテクチャを選択するかは、組織のニーズ、スケーラビリティ要件、構造化データと非構造化データのバランスを考慮する必要性、およびその利点と欠点に依存します。Data Lakehouseは、現代のデータエコシステムの複雑さに対処する企業にとって魅力的なソリューションとなりつつあります。
Miichisoftは、数多くの日本のお客様がビジネス上の課題に効果的に対処できるように支援してきた、高度な資格を持つ開発者チームを擁するテクノロジー会社です。Data Warehouse、Data Lake、Data Lakehouseのテクノロジーを活用したソリューションの開発に豊富な経験を有しています。ビジネスデータに関する問題にお心当たりがあれば、どうぞMiichisoftの無料相談をご利用ください。